
写在前面
最近在使用flink+clickhouse进行业务数据计算和报表统计,但是由于生产的计算结果数过于庞大,前端组件无法一次性接收和展示,而业务需要一次性查出三个月的统计结果的报表进行分析(曲线图),所以在综合考虑后,就引出了ck的采样查询即sample语法,也就是按照特定分组对组内数据进行抽采样后再进行统计,这样就减少了的统计结果,使得前端报表组件得以使用,虽然损失了一定区间内的数据,但是由于是曲线图,所以大体上展示符合真实线条。
由于是第一次接触这种抽象的数据计算,网上又没多少资料,自己手工模拟了不少数据,找到了一定方法和规律,所以特意写出来记一下。
正文
但是这个xcode使用起来太过麻烦,有不少不人性化的设计,所以现在决定使用clion来编译和调试java,所以把过程中需要注意的实现记录下,以便后续参考
官网上这样描述哪些场景需要用到采样查询(上面的例子就是个很好的说明):
- When you have strict timing requirements (like <100ms) but you can’t justify the cost of additional hardware resources to meet them.(当你有严格的时间需求(如<100ms),但你不能通过额外的硬件资源来满足他们的成本)
- When your raw data is not accurate, so approximation doesn’t noticeably degrade the quality.(当您的原始数据不准确时,所以近似不会明显降低质量)
- Business requirements target approximate results (for cost-effectiveness, or to market exact results to premium users).(业务需求的目标是近似结果(为了成本效益,或者向高级用户推销确切结果))
那么如何才能进行采样呢,就是使用sample关键字,首先create table的时候使用sample by来确定采样组,然后再在搜索的时候在表名后使用sample来表示采样搜索,刚详细的说明可以看官方的文档:https://clickhouse.tech/docs/en/sql-reference/functions/hash-functions/
那么最关键的步骤就是确定好sample by后面的表达式,即确定按照哪里列或者方法进行sample。怎样找好sample by,首先就是要了解sample by采样原理
原理(自我测试及理解):ck规定sample by必须是int类型,根据测试,查看ck是拿着我们定义好的sample by,计算每条数据的sample值,想同的值分为一组。在后续select的时候如果加了sample条件,那么就从每个分组内拿指定的条数进行汇总后,再进行后续查询。
如:
1
2
3
4
5
6
7
8
9
10--先对hits_distributed的每个分组取十分之一的数据采样,然后再进行wehre,再进行聚合和排序等
SELECT
Title,
count() * 10 AS PageViews
FROM hits_distributed
SAMPLE 0.1
WHERE
CounterID = 34
GROUP BY Title
ORDER BY PageViews DESC LIMIT 1000
实例如下
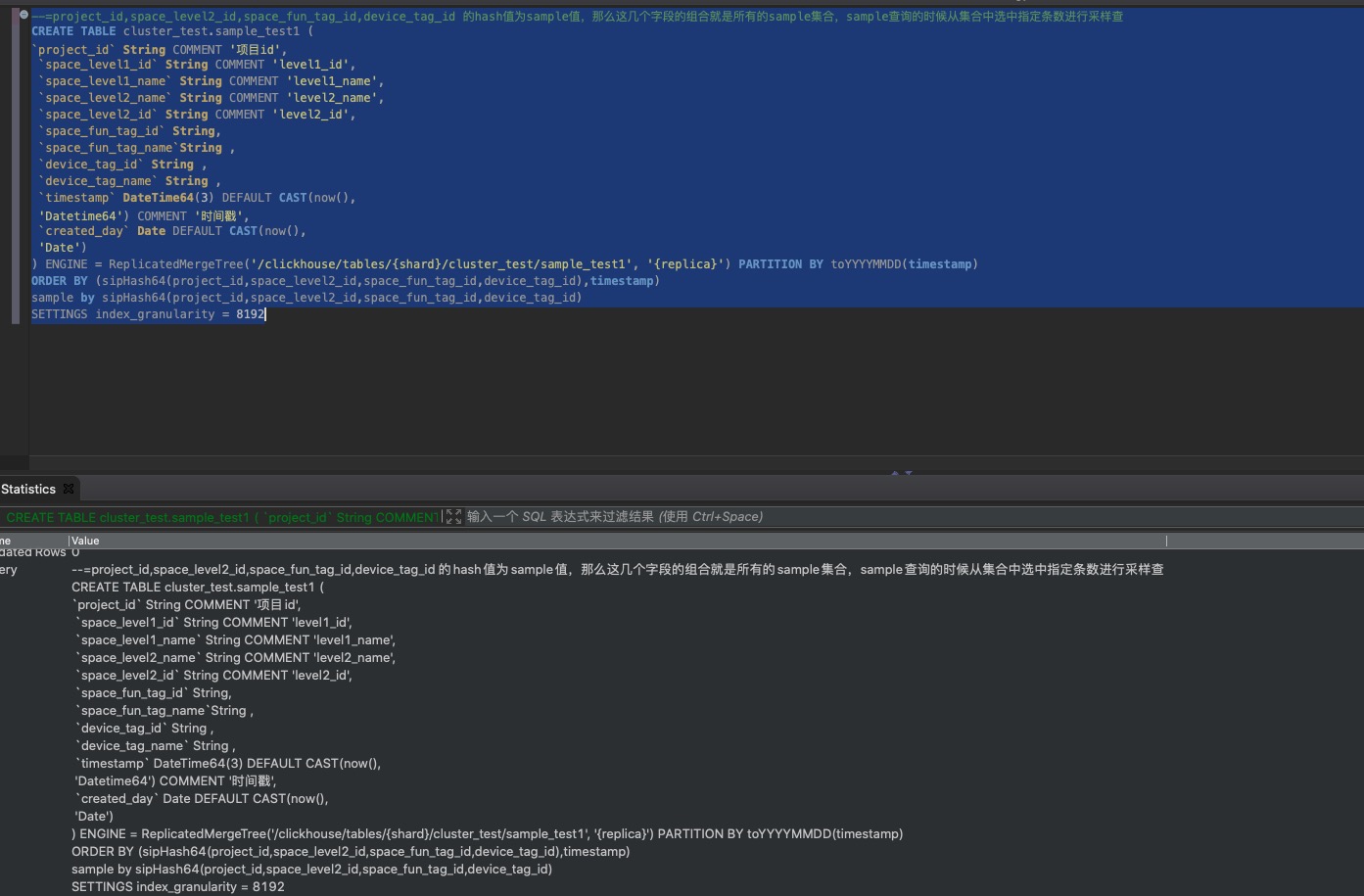
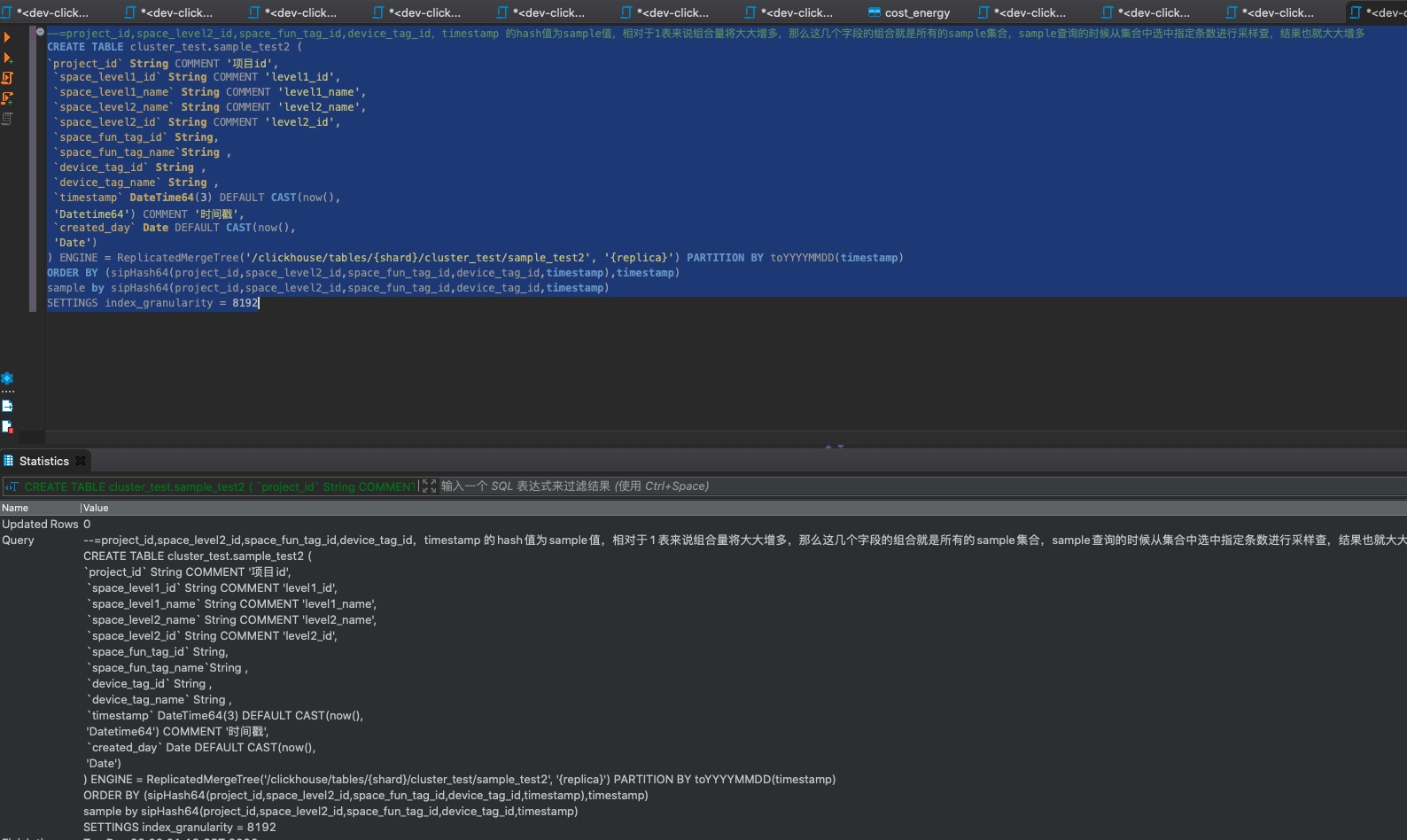
- 有sample1表和sample2表,结构和说明如下:
- 对两个表插入一定的一模一样的数据:
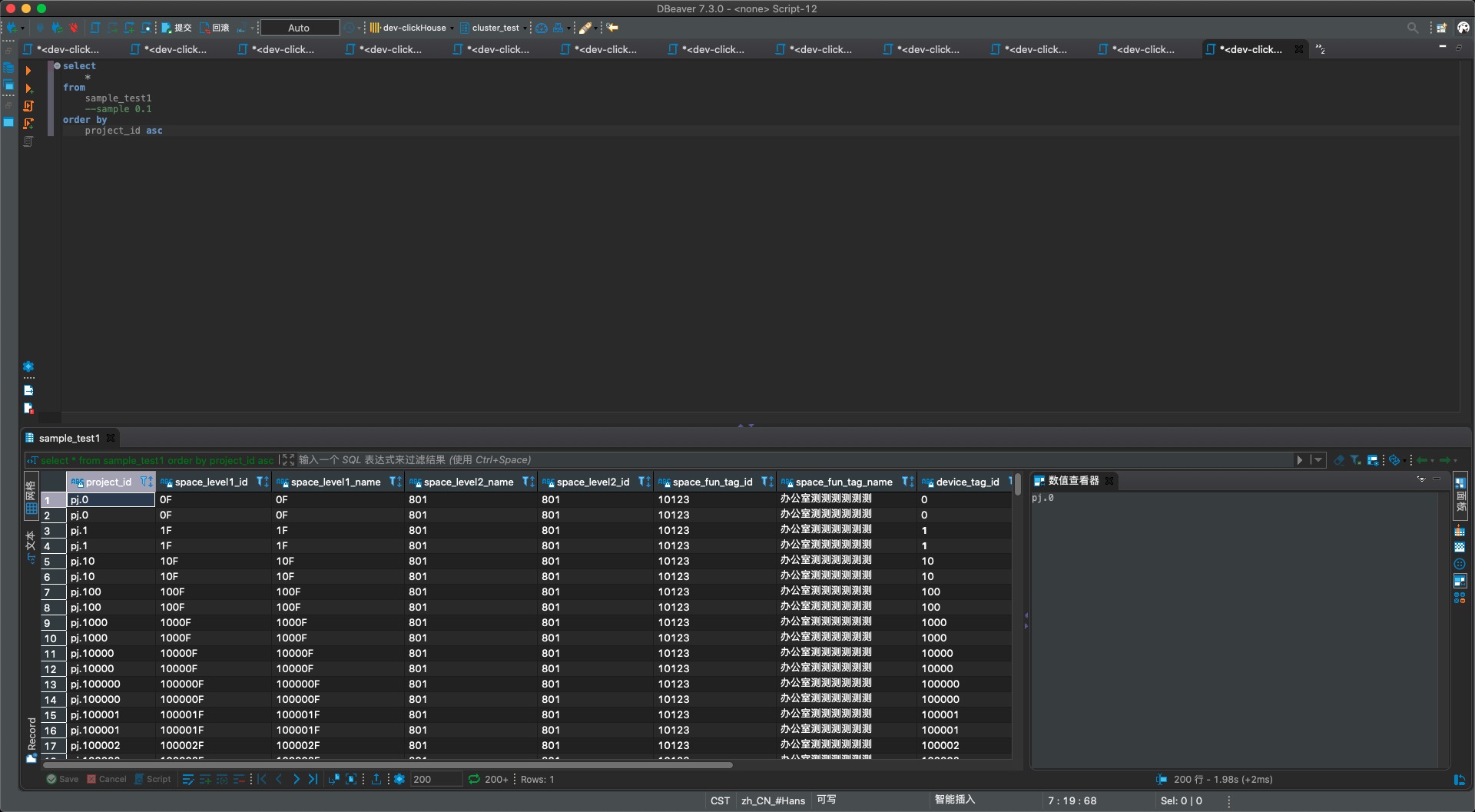
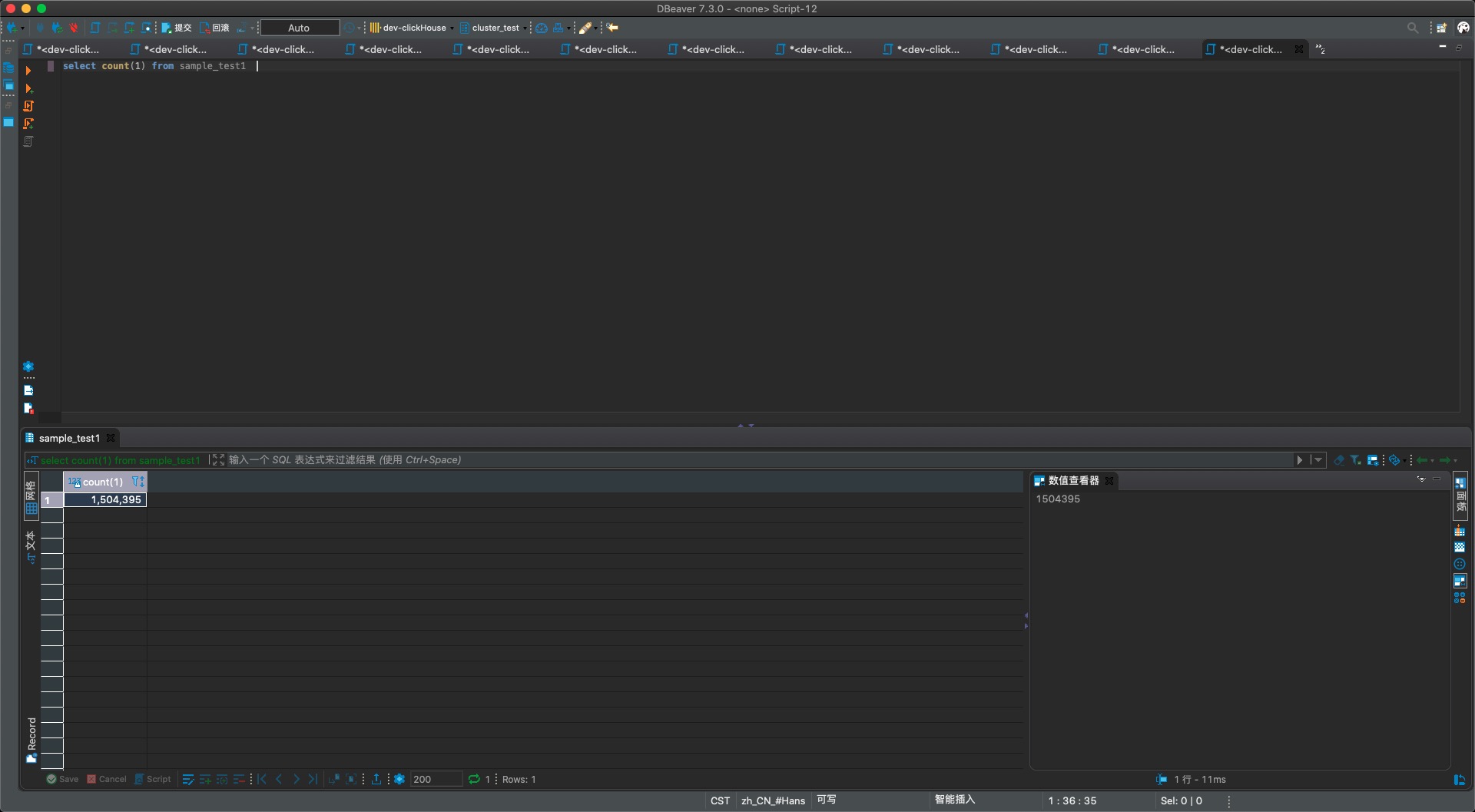
- sample1表的查询结果,可以看到不少项目数据(pj.xx)被采样后丢弃,总数也少了一大堆
- sample2表的查询结果,可以没有项目数据(pj.xx)被采样后丢弃,总数也比s1多了很多
- 有sample1表和sample2表,结构和说明如下:
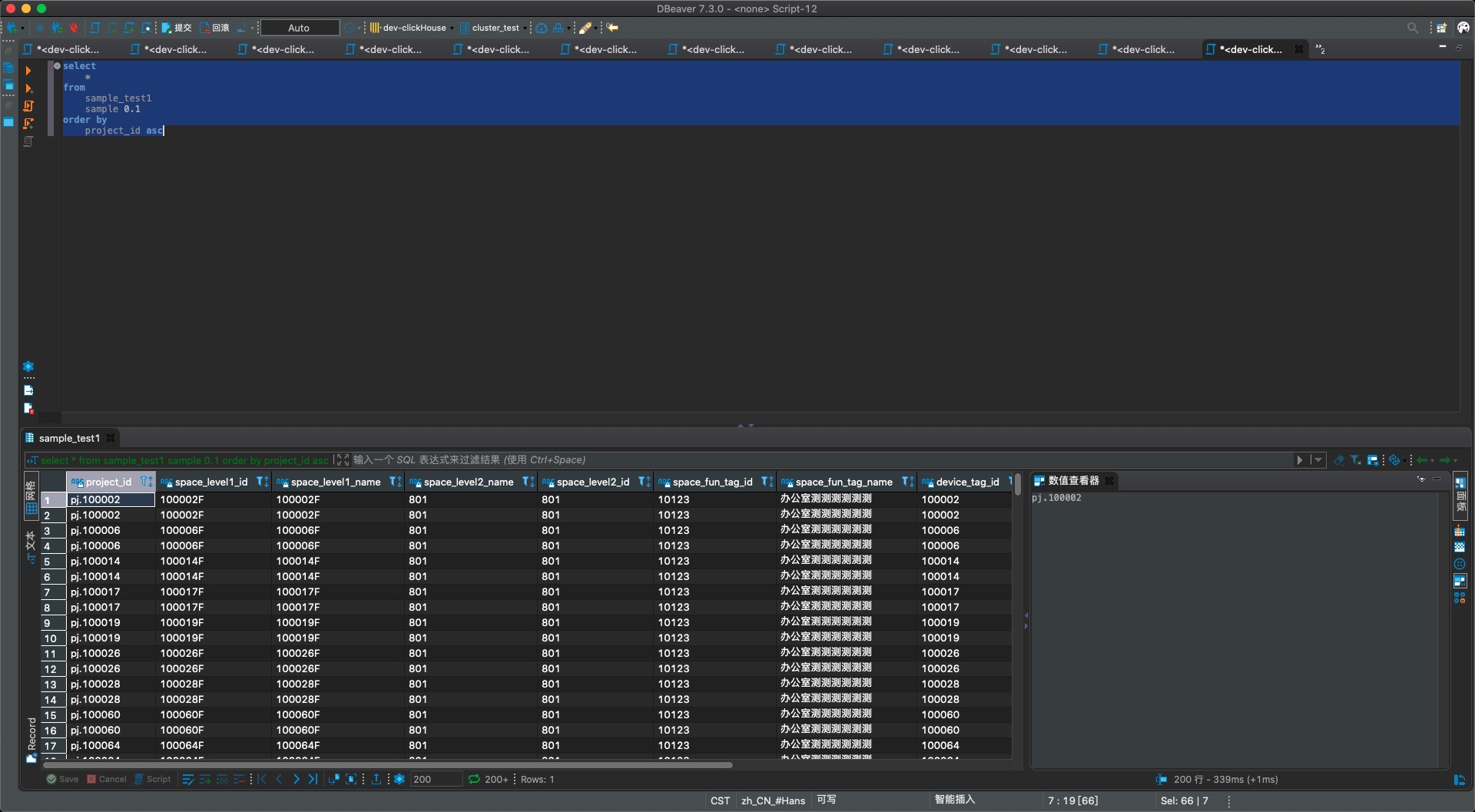
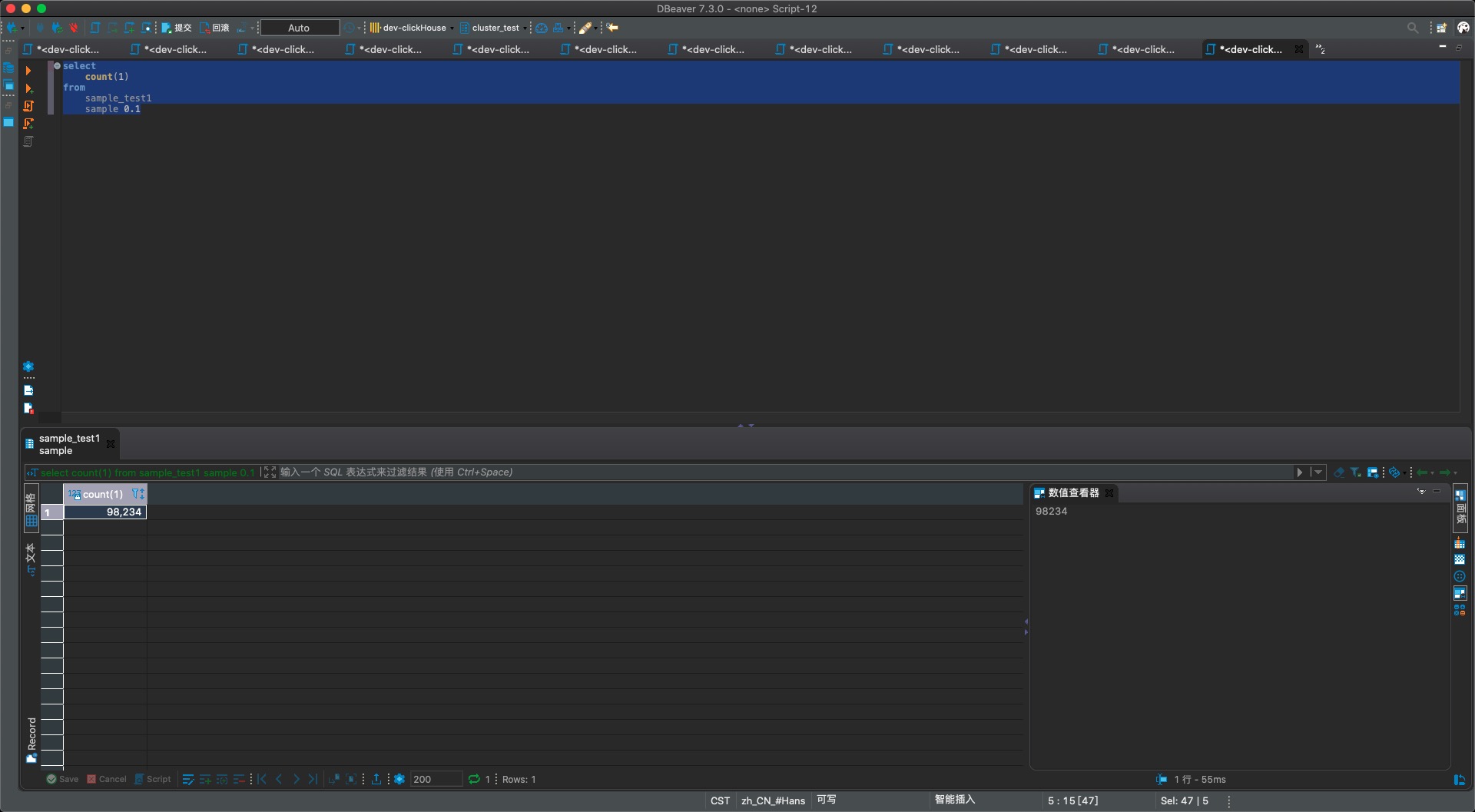
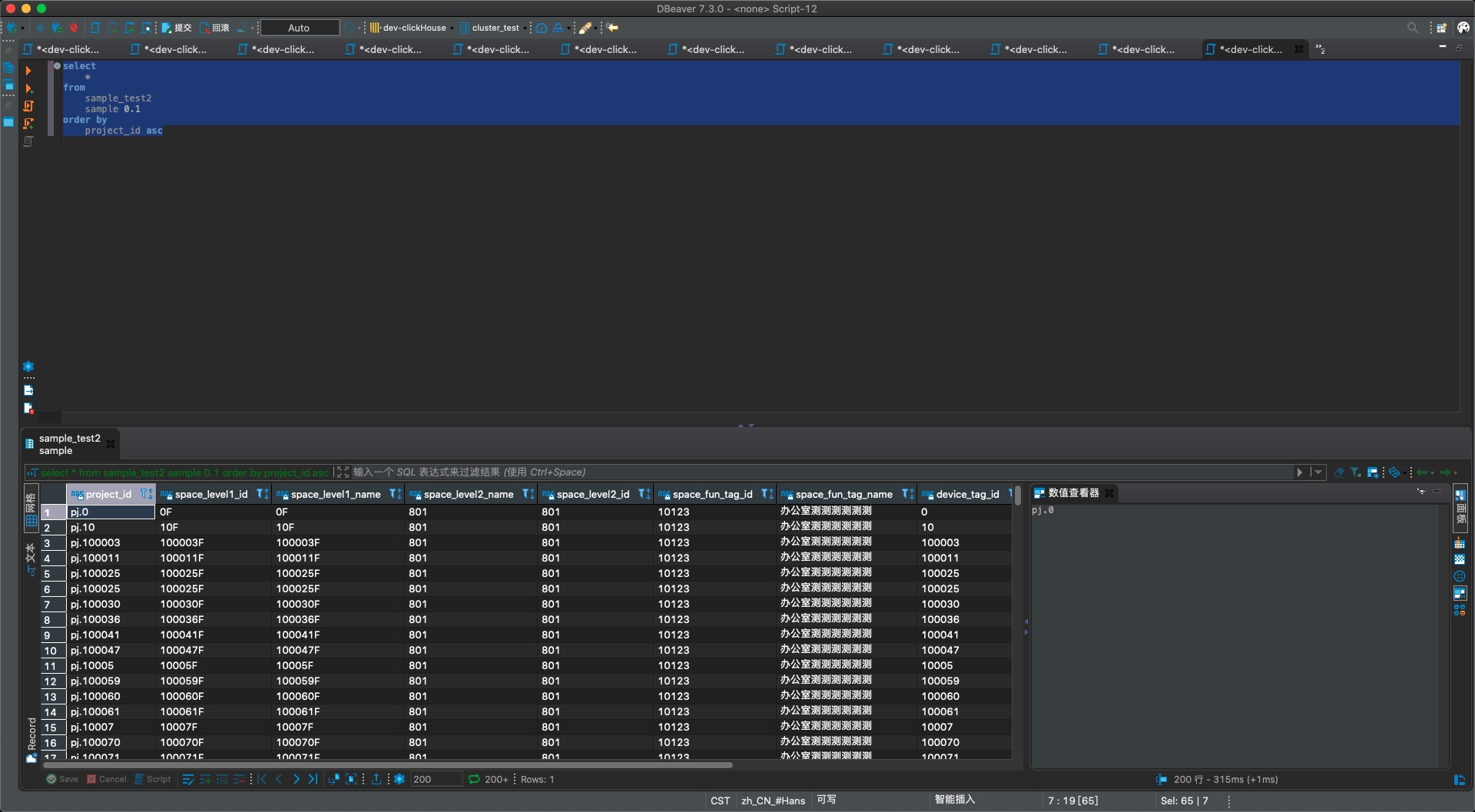
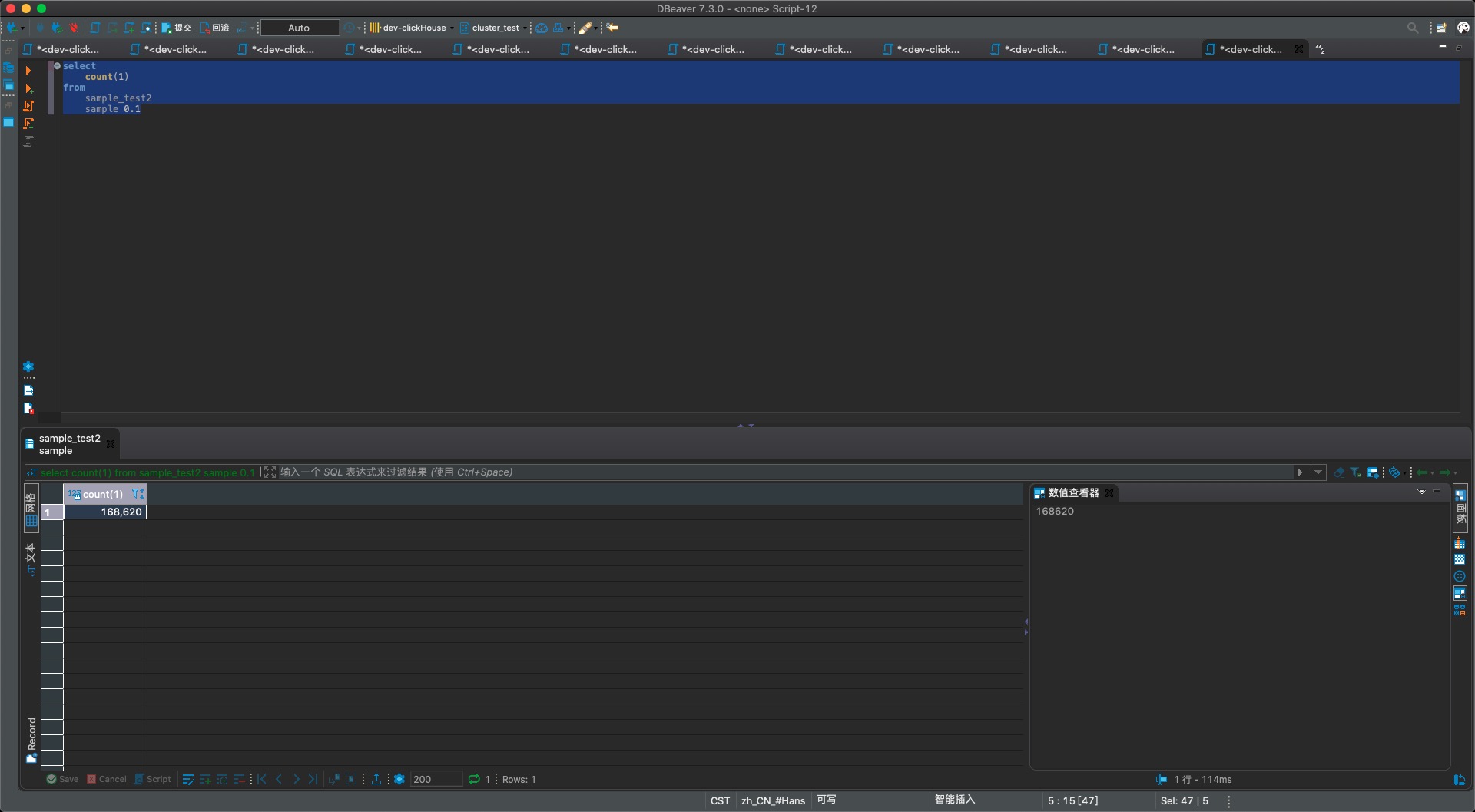
结论验证成功!所以实际工作中,关键是需要确定符合业务要求的sample by,才能满足到业务需求。