
写在前面
之前就用了四篇文章分析了特定场景下GAP锁导致的死锁问题,现生产运行环境的又出现了一次死锁,这次死锁更加诡异,日志如下:
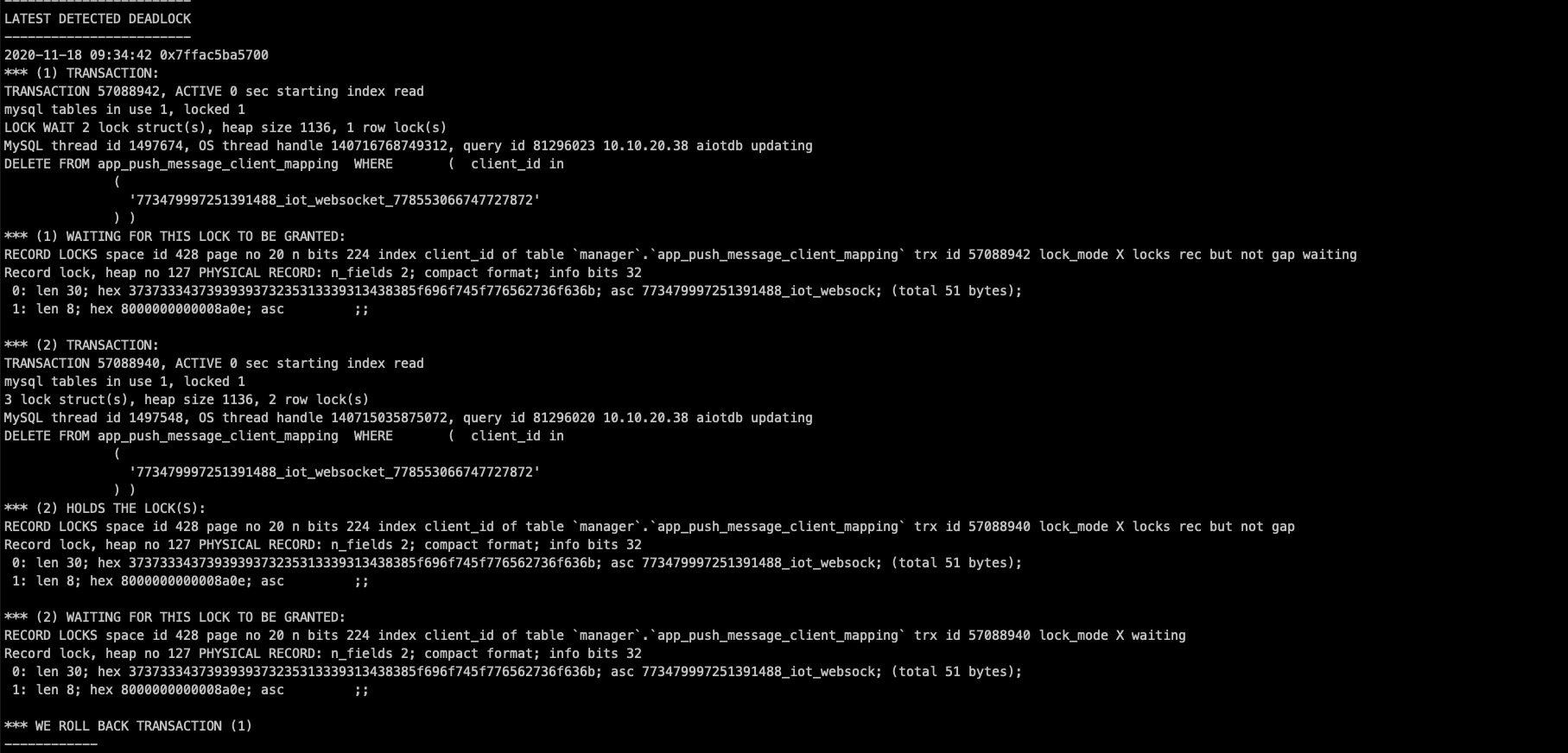
经过长时间排查和查阅资料,终于在本地复现了问题、找到根本原因
正文
第一次拿到这个日志,我是懵逼的额,这和之前遇到的死锁日志完全不同,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42LATEST DETECTED DEADLOCK
------------------------
2020-11-18 09:34:42 0x7ffac5ba5700
*** (1) TRANSACTION:
TRANSACTION 57088942, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 1497674, OS thread handle 140716768749312, query id 81296023 10.10.20.38 aiotdb updating
DELETE FROM app_push_message_client_mapping WHERE ( client_id in
(
'773479997251391488_iot_websocket_778553066747727872'
) )
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 428 page no 20 n bits 224 index client_id of table `manager`.`app_push_message_client_mapping` trx id 57088942 lock_mode X locks rec but not gap waiting
Record lock, heap no 127 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 30; hex 3737333437393939373235313339313438385f696f745f776562736f636b; asc 773479997251391488_iot_websock; (total 51 bytes);
1: len 8; hex 8000000000008a0e; asc ;;
*** (2) TRANSACTION:
TRANSACTION 57088940, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 1497548, OS thread handle 140715035875072, query id 81296020 10.10.20.38 aiotdb updating
DELETE FROM app_push_message_client_mapping WHERE ( client_id in
(
'773479997251391488_iot_websocket_778553066747727872'
) )
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 428 page no 20 n bits 224 index client_id of table `manager`.`app_push_message_client_mapping` trx id 57088940 lock_mode X locks rec but not gap
Record lock, heap no 127 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 30; hex 3737333437393939373235313339313438385f696f745f776562736f636b; asc 773479997251391488_iot_websock; (total 51 bytes);
1: len 8; hex 8000000000008a0e; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 428 page no 20 n bits 224 index client_id of table `manager`.`app_push_message_client_mapping` trx id 57088940 lock_mode X waiting
Record lock, heap no 127 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 30; hex 3737333437393939373235313339313438385f696f745f776562736f636b; asc 773479997251391488_iot_websock; (total 51 bytes);
1: len 8; hex 8000000000008a0e; asc ;;
*** WE ROLL BACK TRANSACTION (1)
------------- 分析
可以看到,死锁的两个事务执行的是同一个语句,并且!可以看到事务二貌似已经持有record锁,还要去再申请record锁,很是奇怪。
因为和之前文章不一样,之前文章是不同sql造成死锁,现如今是同一个sql造成死锁,所以估计是多线程高并发执行同一sql下导致的死锁。
根据此思路,查询资料后找到产生死锁的原理:
原因
1、众所周知,InnoDB上删除一条记录,并不是真正意义上的物理删除,而是将记录标识为删除状态。(注:这些标识为删除状态的记录,后续会由后台的Purge操作进行回收,物理删除。但是,删除状态的记录会在索引中存放一段时间。) 在RR隔离级别下,唯一索引上满足查询条件,但是却是删除记录,如何加锁?InnoDB在此处的处理策略与前两种策略均不相同,或者说是前两种策略的组合:对于满足条件的删除记录,InnoDB会在记录上加next key lock X(对记录本身加X锁,同时锁住记录前的GAP,防止新的满足条件的记录插入。) Unique查询,三种情况,对应三种加锁策略,总结如下:
此处,我们看到了next key锁,是否很眼熟?对了,前面死锁中事务1,事务2处于等待状态的锁,均为next key锁。明白了这三个加锁策略,其实构造一定的并发场景,死锁的原因已经呼之欲出。但是,还有一个前提策略需要介绍,那就是InnoDB内部采用的死锁预防策略。
- 找到满足条件的记录,并且记录有效,则对记录加X锁,No Gap锁(lock_mode X locks rec but not gap);
- 找到满足条件的记录,但是记录无效(标识为删除的记录),则对记录加next key锁(同时锁住记录本身,以及记录之前的Gap:lock_mode X);
- 未找到满足条件的记录,则对第一个不满足条件的记录加Gap锁,保证没有满足条件的记录插入(locks gap before rec);
2、死锁预防
InnoDB引擎内部(或者说是所有的数据库内部),有多种锁类型:事务锁(行锁、表锁),Mutex(保护内部的共享变量操作)、RWLock(又称之为Latch,保护内部的页面读取与修改)。
InnoDB每个页面为16K,读取一个页面时,需要对页面加S锁,更新一个页面时,需要对页面加上X锁。任何情况下,操作一个页面,都会对页面加锁,页面锁加上之后,页面内存储的索引记录才不会被并发修改。
因此,为了修改一条记录,InnoDB内部如何处理:
- 根据给定的查询条件,找到对应的记录所在页面;
- 对页面加上X锁(RWLock),然后在页面内寻找满足条件的记录;
- 在持有页面锁的情况下,对满足条件的记录加事务锁(行锁:根据记录是否满足查询条件,记录是否已经被删除,分别对应于上面提到的3种加锁策略之一);
死锁预防策略:相对于事务锁,页面锁是一个短期持有的锁,而事务锁(行锁、表锁)是长期持有的锁。因此,为了防止页面锁与事务锁之间产生死锁。InnoDB做了死锁预防的策略:持有事务锁(行锁、表锁),可以等待获取页面锁;但反之,持有页面锁,不能等待持有事务锁。
根据死锁预防策略,在持有页面锁,加行锁的时候,如果行锁需要等待。则释放页面锁,然后等待行锁。此时,行锁获取没有任何锁保护,因此加上行锁之后,记录可能已经被并发修改。因此,此时要重新加回页面锁,重新判断记录的状态,重新在页面锁的保护下,对记录加锁。如果此时记录未被并发修改,那么第二次加锁能够很快完成,因为已经持有了相同模式的锁。但是,如果记录已经被并发修改,那么,就有可能导致本文前面提到的死锁问题。
以上的InnoDB死锁预防处理逻辑,对应的函数,是row0sel.c::row_search_for_mysql()。感兴趣的朋友,可以跟踪调试下这个函数的处理流程,很复杂,但是集中了InnoDB的精髓。
3、剖析死锁的成因
做了这么多铺垫,有了Delete操作的3种加锁逻辑、InnoDB的死锁预防策略等准备知识之后,再回过头来分析本文最初提到的死锁问题,就会手到拈来,事半而功倍。

上面分析的这个并发流程,完整展现了死锁日志中的死锁产生的原因。其实,根据事务1步骤6,与事务0步骤3/4之间的顺序不同,死锁日志中还有可能产生另外一种情况,那就是事务1等待的锁模式为记录上的X锁 + No Gap锁(lock_mode X locks rec but not gap waiting)。
上面分析来自博客:https://blog.csdn.net/tr1912/article/details/81668423