写在前面
hbase的Rowkey根据不同业务需求可能设计成各式各样的格式,因为业务复杂多变,所以除了最基础的那些原则,另外一般是根据搜索频率、搜索有效性质来排序拼接成rowkey,在最近开发中设计了一个操作日志表,设计的rowkey为:操作Id+时间戳+模块。这样做可以快速搜索到某个人的操作日志,但是在实际测试中却遇到了一个查询数据丢失的问题。
正文
首先去hbase,直接shell执行scan:
得到结果发现hbase本身并没有数据丢失,如下:
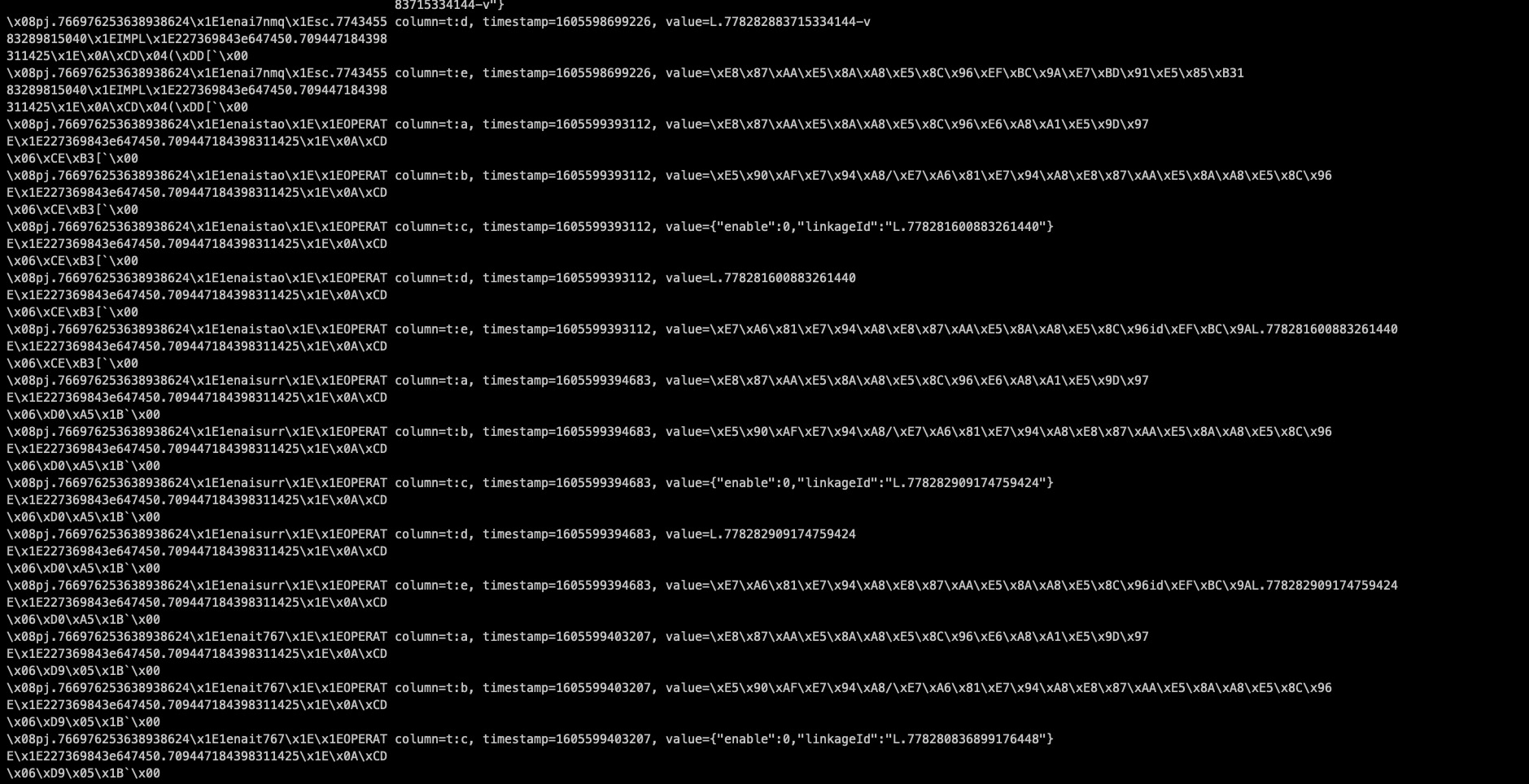
而且可以看到scan的结果是按照时间戳正序排序的。那么再跟踪代码中看到构建scan start key和end key的时候是这么构建的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
scan.setReversed(true);
startKey = generateUserLogScanRowKey(projectId, condition.getEndTime());
stopKey = generateUserLogScanRowKey(projectId, condition.getStartTime());
public static byte[] generateUserLogScanRowKey(String projectId, long timestamp) throws Exception {
if (StringUtils.isEmpty(projectId) || timestamp == 0L) {
throw new Exception("projectId and timestamp不能为空");
}
int salt = Math.abs(projectId.hashCode() % 9);
byte[] projectBytes = BizByteUtil.string2Bytes(projectId);
int projectLength = projectBytes.length;
byte[] timeBytes = HbaseResourceUtils.serializeResourceTimestamp(timestamp);
int timeLength = timeBytes.length;
byte[] rowKey = new byte[projectLength+timeLength+3];
rowKey[0] = (byte)salt;
System.arraycopy(projectBytes, 0, rowKey, 1, projectLength);
rowKey[projectLength+1] = ROW_KEY_INVISIBLE_SEPARATOR_CHARACTER;
System.arraycopy(timeBytes, 0, rowKey, projectLength+2, timeLength);
rowKey[projectLength+timeLength+2] = ROW_KEY_INVISIBLE_SEPARATOR_CHARACTER;
return rowKey;
}
|
经过分析发现了问题所在:可以看到构建代码中rowkey仅仅构建了操作id和时间戳,而真实的rowkey却是三位,少了一位,那么从start开始扫的时候绝对会遗漏数据,为了方便理解,画个简单的图来展示:
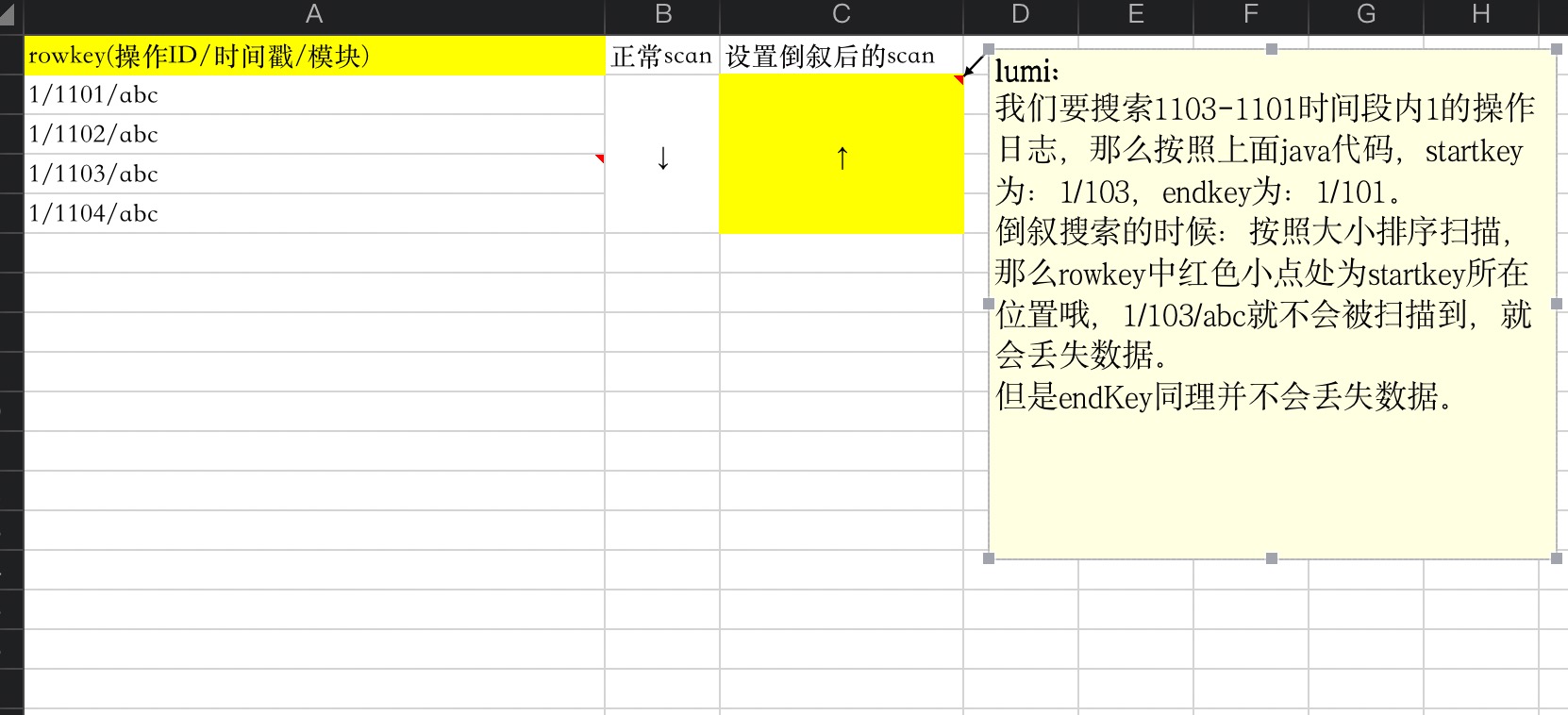
那么该如何解决呢?这里想到了一个解决思路:扩大startkey的最后一位,如1/103变为1/104,并扫描后判断是否为需要数据,不是则抛弃。
具体代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
biggerScanRowKey(startKey);
public static void biggerScanRowKey(byte[] rowKey) {
for (int i=rowKey.length-1; i>=0; --i) {
if (rowKey[i] != Byte.MAX_VALUE) {
rowKey[i]++;
break;
}
}
}
Result result = resultScanner.next();
while (null != result) {
if (shouldValidateBigger && !ResourceManagerImpl.validateRowKey(result.getRow(), scanner.getBiggerBytesOriginal())) {
result = resultScanner.next();
continue;
}
}
|
这样操作的话就可以使得数据不丢失。
当然结合上面所说,如果是正序scan,那么需要做的是放大endkey,在扫描后判断rowkey和endkey的大小,大于的话就直接跳出循环,说明扫描到头了~
问题解决~
