写在前面
接上文,本文主要是对复现的场景仔细分析下,如何会产生死锁以及该怎么避免?以及后续的思考
正文
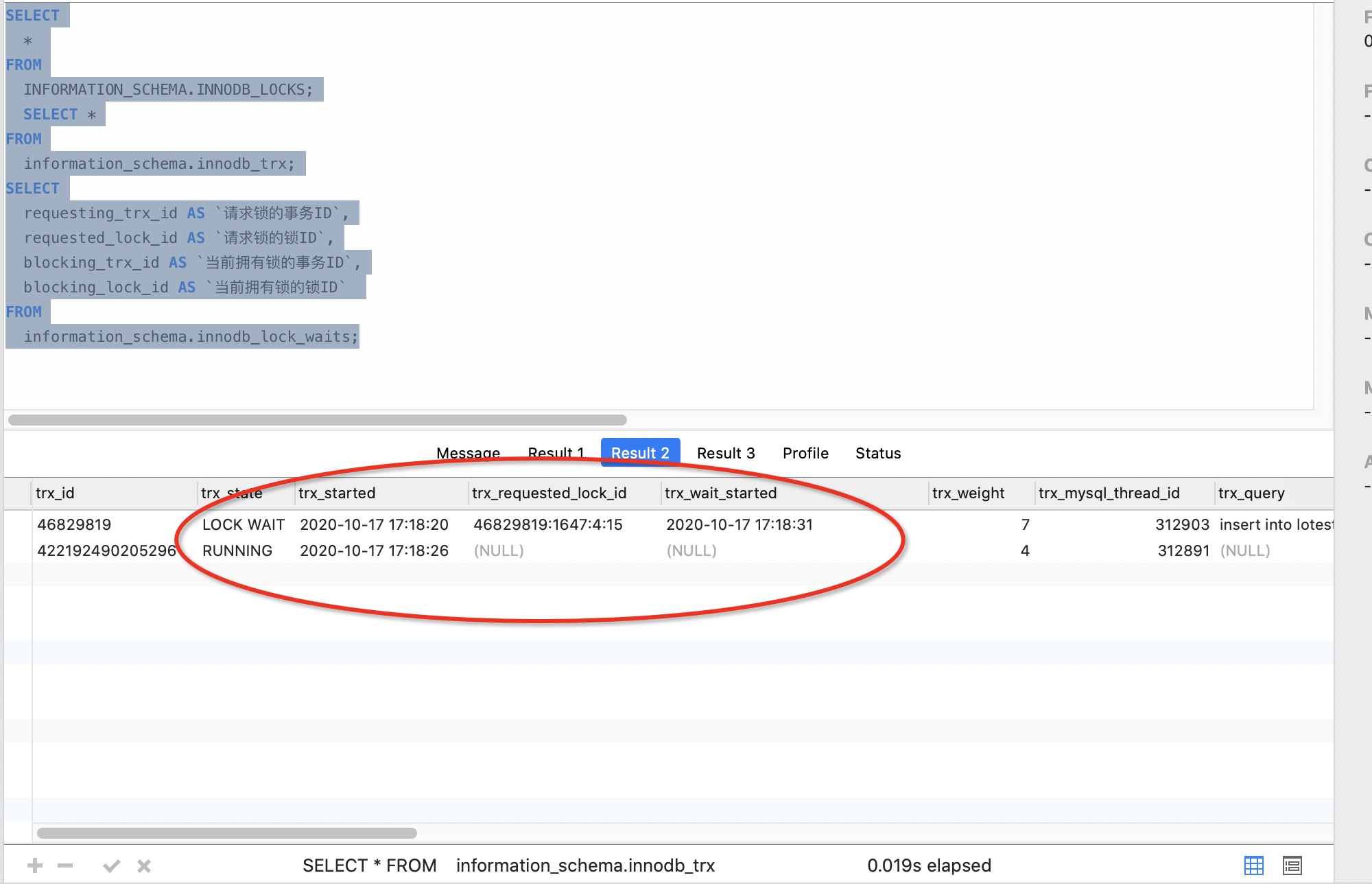
接下来我们有机会一步步分析下为什么会出现死锁(因为锁等待50s会自动关闭事务,所以截图内的事务id某个步骤会变化,但是不影响问题分析)
第一步:事务1:select * from lotest where type=’B20’ lock in share mode;
- 日志如下(无锁等待):
- 日志如下(无锁等待):
第二步:事务2: select * from lotest where type=’B20’ lock in share mode;
- 日志如下(亦无锁等待):
- 日志如下(亦无锁等待):
第三步:事务1:insert into lotest (type) values(‘B20’);
- 日志如下(产生锁等待):
- 日志如下(产生锁等待):
第四步:事务2:insert into lotest (type) values(‘B20’);
- 直接死锁,死锁日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31*** (1) TRANSACTION:
TRANSACTION 46829918, ACTIVE 107 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 6 lock struct(s), heap size 1136, 4 row lock(s), undo log entries 1
MySQL thread id 312903, OS thread handle 140715008841472, query id 16235443 10.11.33.169 root update
insert into lotest (type) values('B20')
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
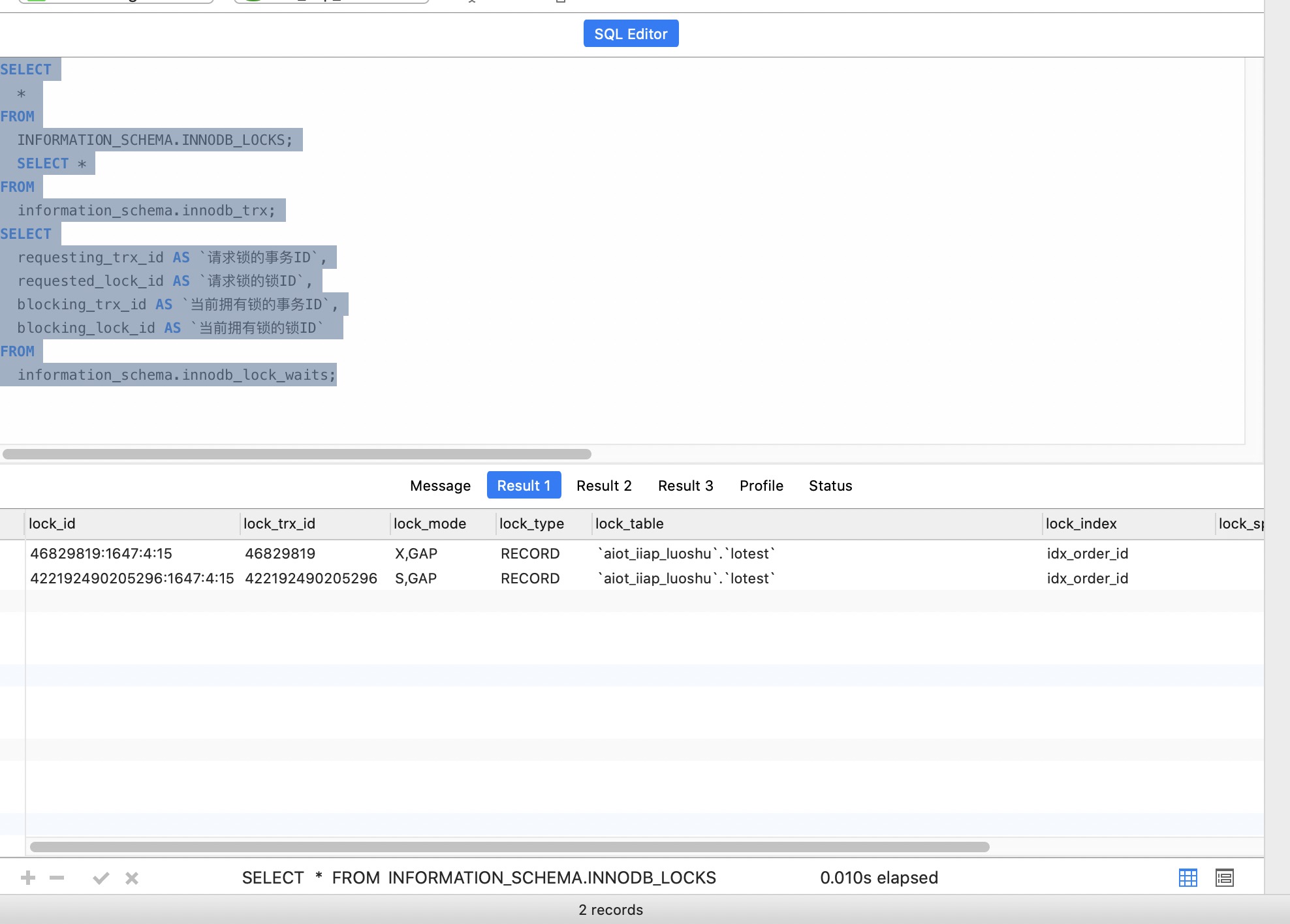
RECORD LOCKS space id 1647 page no 4 n bits 88 index idx_order_id of table `aiot_iiap_luoshu`.`lotest` trx id 46829918 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 15 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 3; hex 423330; asc B30;;
1: len 6; hex 00000010f442; asc B;;
*** (2) TRANSACTION:
TRANSACTION 46829919, ACTIVE 297 sec inserting
mysql tables in use 1, locked 1
6 lock struct(s), heap size 1136, 4 row lock(s), undo log entries 1
MySQL thread id 312891, OS thread handle 140714847319808, query id 16235444 10.11.33.169 root update
insert into lotest (type) values('B20')
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 1647 page no 4 n bits 88 index idx_order_id of table `aiot_iiap_luoshu`.`lotest` trx id 46829919 lock mode S locks gap before rec
Record lock, heap no 15 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 3; hex 423330; asc B30;;
1: len 6; hex 00000010f442; asc B;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 1647 page no 4 n bits 88 index idx_order_id of table `aiot_iiap_luoshu`.`lotest` trx id 46829919 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 15 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 3; hex 423330; asc B30;;
1: len 6; hex 00000010f442; asc B;;
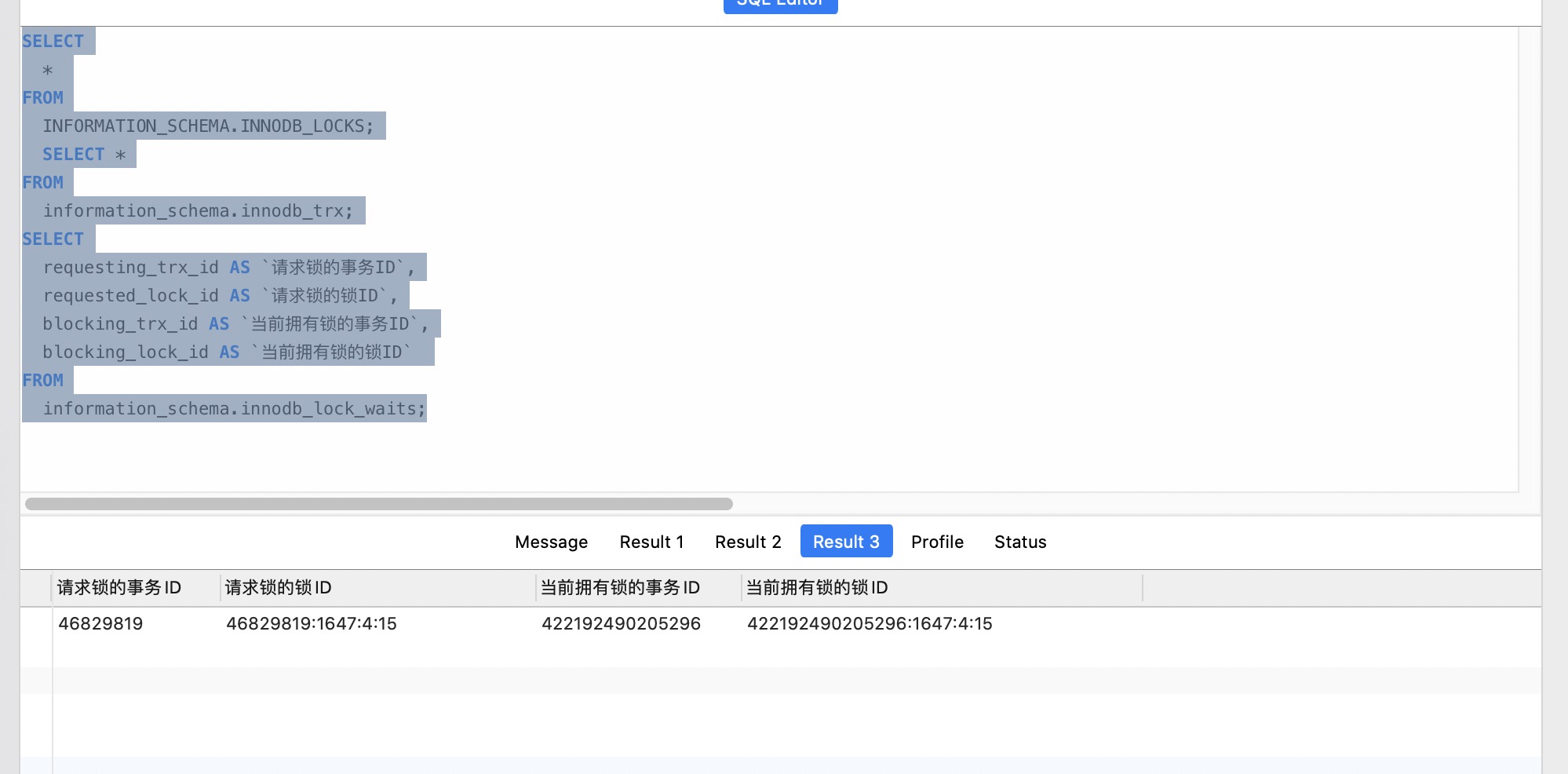
*** WE ROLL BACK TRANSACTION (2)一步步根据日志来看,我大概总结了为什么会产生死锁,画出来如下:
 。
。这样的话整个逻辑就清晰明了~
关于上段锁的等待和排斥关系图总结如下:
 。
。
思考和解决方案:
- 可以看到我们上面最关键的是事务1和事务2都获得了相同记录或位置的、可共享的低级别的锁,然后同时申请相同记录或位置的、不可共享的锁就会引起锁相互等,从而被innodb判定为死锁,回滚了权重更低的事务
- 经过排查代码果然发现在程序里里发现了如下一段代码:
 。
。
- 虽然这种场景很难遇见,但是一旦出现就会导致数据不一致甚至丢失,问题还是很严重的,所以平时开发过程中需要注意避免这种写法
- 解决思路:删除之前,可以先查询下,有的话再删除,这个时候获得的锁是指定记录的X行锁,会阻塞其他线程获取低级别的锁,从而防止死锁的出现
- 把delete等共享锁获取语句抽取出事务,单独执行
写在后面
大家获取纳闷为什么真实代码里是delete,其实它和前面演示的是select * * lock in share一样,在innodb未找到记录的情况下。RR级别的时候为了防止多事务造成误删除,同样会获取到间隙共享锁。
前一篇表格也列举了,死锁总结来说就是两个或更多事务同时获得了某个行的共享锁,然后又同时需要申请这个记录行的排斥锁,引发相互等待从而死锁。
我自己分析可能的现实场景分为如下两类:
1、第一步:有无记录都可以的:select *lock in share (同时获得某个共享锁)
第二步:insert ;有记录的update和delete(无记录的update和delete也只是会升级到可共享的间隙锁,不会死锁)
2、第一步:无记录下的update和delete(同时获得相同共享锁)
第二步:insert (同时申请一个相同的排斥锁)